
I've been building voice apps more than I expected lately.
It wasn't a part of the tech space I really cared about.
Voice has been the sleepiest corner of tech for what feels like forever.
Siri totally sucks.
Google has had some ok experiences if you where an android user.
Not a lot of business use cases.
But that all changed when Open AI launched Whisper, their Speech To Text ( STT) model that can cheaply and effectively turn human voice into text. A large barrier to building anything useful before.
It again got even more interesting when they launched ChatGPT Voice on iPhone in 2023 giving me and everyone else a concrete example of what the experience of a voice interface could look like with these new tools.
This pushed me over the line. Voice was now something I wanted to build with.
Technically, a while back, I built a little voice based language learning app to help me learn Spanish while reading books and blogs. But after I built it it sucked so bad that even I didn't like it so I shelved it and never tried to get customers.
Here's a demo video of how bad the voice stuff worked then ( Sept 2021 )
You can tell after 30 seconds how this is not going well.
The ability to get good text output from me talking in poor Spanish or even in good English was just not good enough.
This was using the Web Speech API which is essentially a browser native set of functions you can call in any browser and the browser relay's that voice data to a server to be processed. In most cases sending it to google.
Now that we have whisper, along with a ton of other models, we can build high quality audio experiences that don't suck.
For example here is a demo of a new language learning app I built on iOS after proving the tech could work using GPT Voice and a good prompt. Essentially picking that old idea off the shelf and dusting it off with some new technology.
You can tell that now, basically the same experience I was aiming for 3 years ago works, and we can do voice response without it sounding like Microsoft Sam.
My Spanish is not great but the model does really good with it anyways. It's fairly fast, and now we have voice feedback vs just text. This also recently became economically possible when OpenAI released their Text-To-Speech ( TTS ) service.
Text to Speech had existed for some years and in high quality but could only really make economic sense for things like voiceovers, audiobooks, or media where you "print" the audio out once and reuse it whereas this app is live streaming hours of just in time voice to the user.
For example I did some rough math on if this new products margins could work out.
This is the math for top TTS models at the time if the user used it 1 hr per day over a month.
Eleven Labs = $117.72
Resemble AI = $340.92
Open AI TTS = $13.09 ( 🤯 Big difference right? )
Now there are a lot more options and prices have got even better.
The point is OpenAI TTS was a big leap in affordability and $13 / month per user meant we where just starting to get into the territory that someone might actually be willing to pay enough for an education app and you could make some margin as a business.
Basically, you should consider programmatic intelligent human conversation to be both free and easy going forward in the future.
Ok enough story time.
Time to go over what I learned from iterating on voice products to help you skip my mistakes.
Part 2 - Building AI Voice apps as an uninformed beginner
The core AI models of a voice app are as follows:
Speech-to-text model -> LLM for intelligence -> Text-to-speech model to generate speech.
This makes the core loop.
You receive audio, you turn it into text, you feed the text to an LLM to generate a response, you feed the text into a TTS model and return audio.
It looks like this.
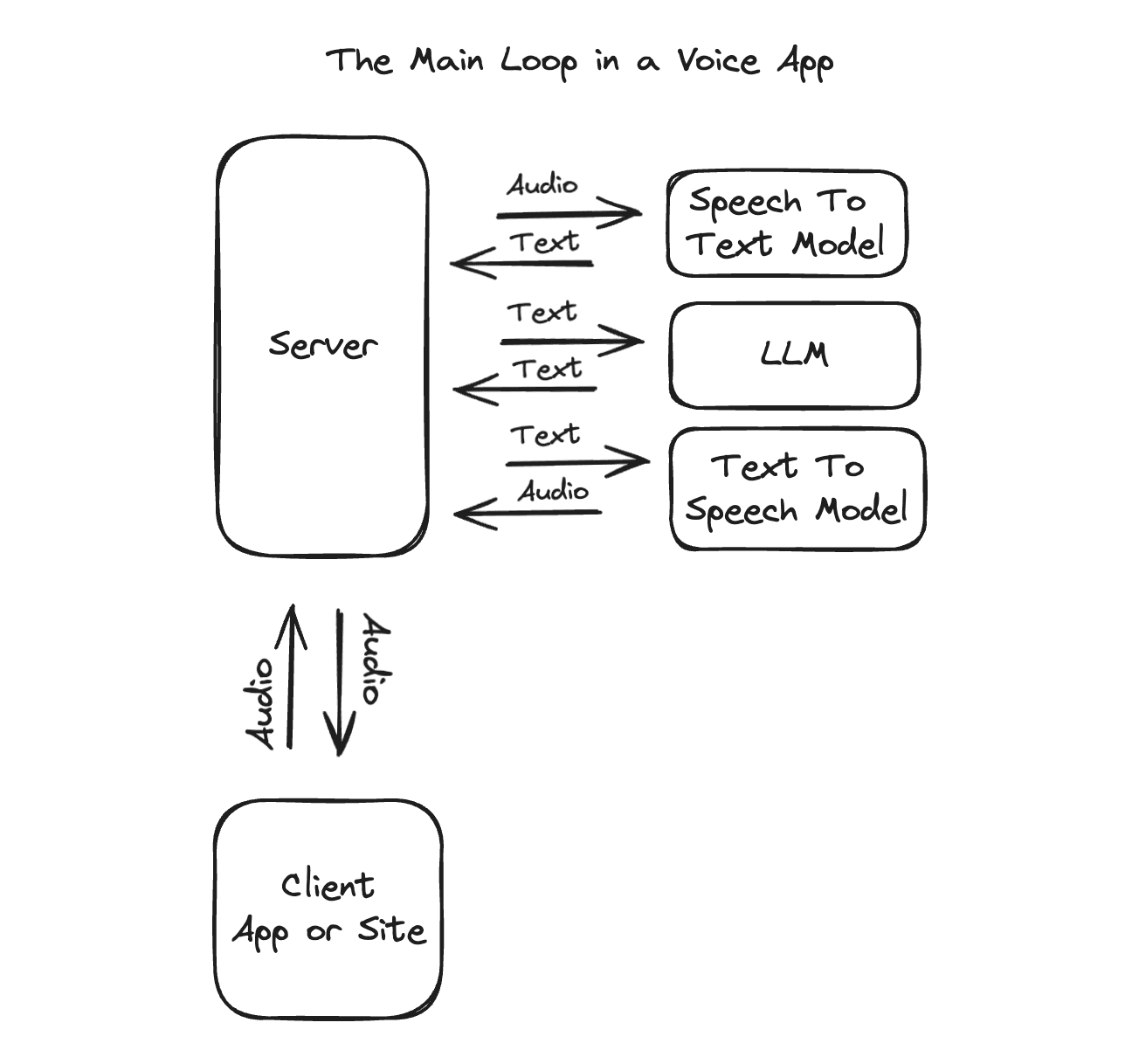
Just to be warned this is the main loop right now but it is already changing.
We are already seeing models that do Voice-To-Voice to maintain emotion and inflection as well doing the LLM "intelligence" work and models that stream in and out at the same time to provide model level "interruptions" management natively.
Next up we have your option of pipes:
TLDR: You should use WebRTC.
If you are doing "push to talk" where the user is doing something more akin to sending an audio Whatsapp message you can use any old REST API.
Record audio locally -> Upload to server -> Return Audio response
Speed matters less in this user experience model and you don't need to worry about data loss or buffers or other gross stuff.
When I started building Nuance ( the new Spanish app ) I started this way. I made a simple rest server and sent the data up and back down. I had never done any real work with streaming audio so I just did what I knew.
Honestly it worked ok. But as more voice apps came out I quickly decided my stuff sucked and it needed to be faster.
I also wanted to add streaming text responses and decided a rewrite was in order.
I do too many rewrites but thats a different blog.
For the next version I chose websockets because I had used that before and new it could work and here's why you shouldn't.
Even though it can work ok. It is, in fact, what is running the second video I showed you it is complicated to get right and going this route makes your code and product worse in every dimension compared to using WebRTC.
First off WebRTC manages inconsistency in network speed automatically and Websockets do not.
If you use Websockets from scratch not only do you just accept some data loss you need to hand manage difficult to control, inconsistent, incoming and outgoing streams of data.
The current version of Nuance has a habit of some light "squeaks" in the audio regularly because of this.
You have to go deep into the world of hz, sample rates, circular buffers, etc to modify raw audio in a way that works for your server, client, iOS, and buffer things in a way that provides enough "backpressure" to somewhat reliably get smooth playing streaming audio on the client.
This sucks.
Its a hell of a learning experience but let me tell you I think your better off learning something else. There be dragons here. 🐉
You end up with lots of messy code on the client ( at-least for iOS, but I think for web also ) because the entire ecosystem of smart open source developers focus on good implementations of WebRTC vs good implementations of audio over Websockets because it's literally exactly what WebRTC is made for.
WebRTC does require that you pay for a WebRTC provider of some sort but the free tiers are ok and the costs will be less then your server hosting costs of whatever probably not great Websocket server implementation you create.
I've never had so many memory leaks in my life!
Ok so we have gone over most of the core pieces now but now is time for the final boss.
Voice Activity Detection ( VAD ).
Voice activity detection is how the application knows when a user has started or stopped talking.
In my case I wanted the user to be able to set the phone down next to them and read a book out loud to the AI for an hour without ever having to touch a button or look at the screen.
The app needed to handle the "handoff" of going from the users turn to speak to the computers turn to speak.
It had to be reliable and it had to work with air conditioning running and dogs barking on the street.
My first version was such a hack its crazy it worked at all.
It was totally local. Used a scoring system based on audio levels and the speed at which Apples native TTS created coherent words.
It WAS a hack but worked ok.
On iOS I think well funded people use CoreML to do stuff like this but to me a simple open source solution never became obvious and I couldn't grasp a good way to go that route.
But the hack was a hack and deteriorated as my expectation grew.
It had trouble with lots of edge cases in the Spanish language and the accidental handoffs where frustrating enough to make you not enjoy the product.
Solution number two.
I new without using CoreML my next best option was to start doing VAD on the server.
This is also part of why the REST to Websocket rewrite had to happen.
I needed to stream data to the server so the server could tell the client when to handoff.
Luckily once on the server we have more good options on how to build a VAD.
The most battle tested VAD on the market is actually the VAD that exists inside the native implementation of WebRTC.
I was expecting it to work similar to how the Web Speech API worked.
Basically you just talk to it and it sends you a little notification when the user stops speaking.
Not so lucky.
When working with the VAD directly at least the way I got it to work in Javscript it required a lot more management.
First off. I needed to pre clean the data which required using FFMPEG to do some simple audio cleaning like getting rid of data too high or too low to be human speech. No magic just math.
Then the VAD is really chatty. It doesn't just send you a 'user started' or a 'user stopped' it sends you a result of NOISE, HUMAN, NONE basically more than 100 times per second and it's your job to tease out what that needs to mean for your application.
Here again I built a scoring system.
It was tricky but I got it working nearly flawlessly.
Other than code complexity other losses here is the need for my docker build to now have Python for FFMPEG audio cleaning.
Yes I still write my AI apps in Typescript.
Well at least I was still then.
Ok so now we have taken you through most of the headaches you would run into if you started where I did and made the same decisions.
Now lets talk about what a good implementation looks like today with all your newly acquired experience.
Part 3 - How to build AI Voice apps now that you have some experience.
I alluded in Part 2 that AI models where changing, you should use WebRTC and that Voice Activity Detection ( VAD ) should be a core consideration of your product.
So how am I building now and how should you?
Here's the reason behind each choice and the benefits it provides followed by a list of actual tools to help you do it.
WebRTC
WebRTC is designed as a protocol to make streaming Audio, Video and whatever JSON you want over the web work well even when on a phone with bad data.
WebRTC has a mature ecosystem of client libraries for all languages that matter.
WebRTC has lots of infra providers to choose from.
Most importantly WebRTC will make it easier for you to adopt new AI models with changing demands in the future.
When you build with WebRTC the client and the server are actually both essentially dialing into a meeting. Think of it like joining a zoom call.
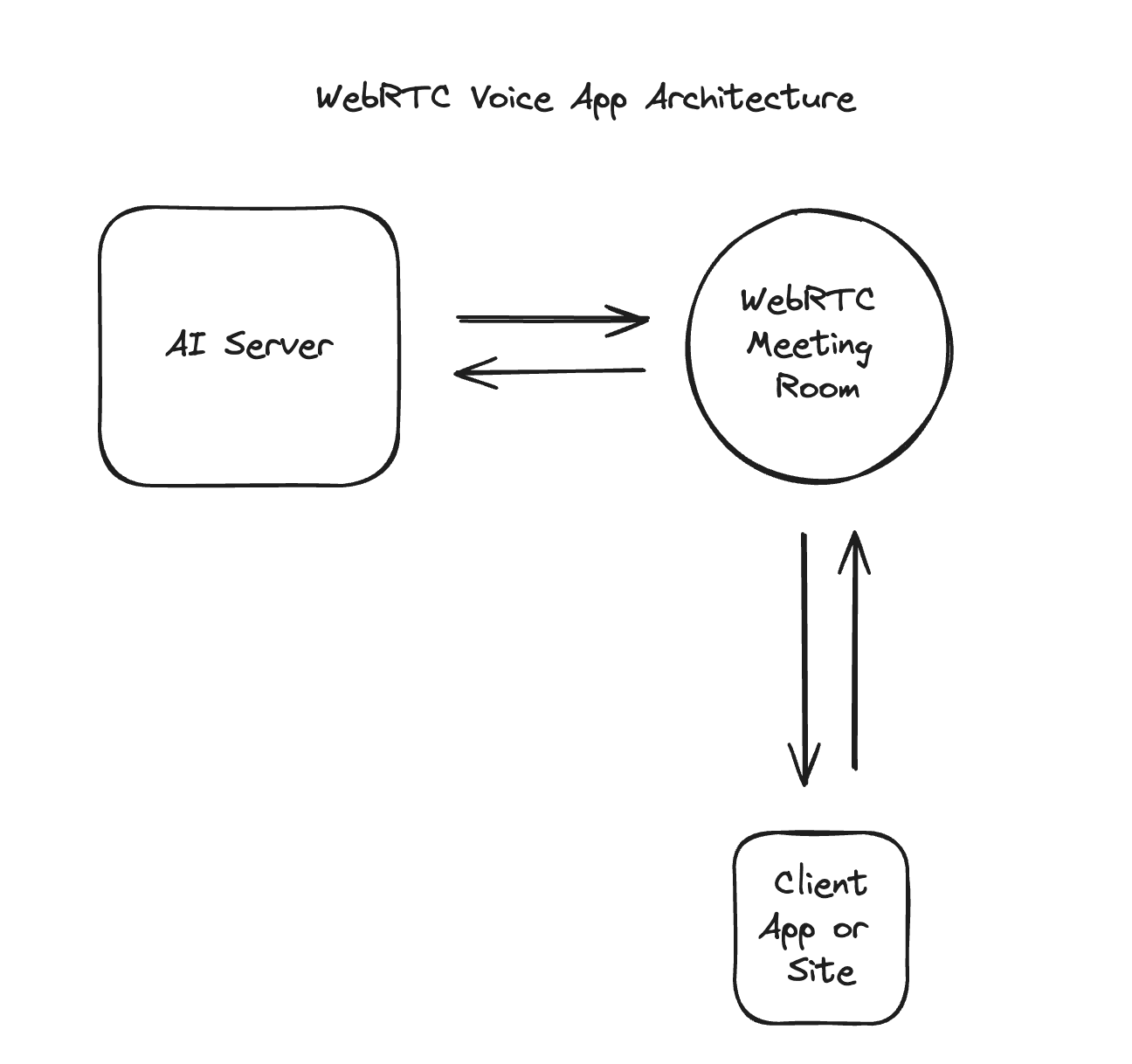
Compared to Websockets or REST this leaves you completely open to how to manage handoffs, "interruptions", or other forms of media in the future as models change.
Anything that needs to change on the AI side is just getting pumped into the room and consumed by the client side WebRTC SDK.
You approach zero changes needed to add sending images, random JSON or expanding to allow multiple AI's or multiple users into a single chat.
WebRTC will also help you easily manage a migration to Voice-To-Voice models that expect bi-directional same time data streams in the future.
WebRTC Infra Providers:
Daily.co ( Used by Me, and Vapi )
LiveKit ( Used by OpenAI )
LLM, TTS and STT Models
The most important consideration for models will be tightly tied to your project goals.
If speed is your most important feature you will need models that can all stream.
You will need hosts that can do this fast and cheap.
Your language and safety requirements will help you choose too.
Whisper doesn't really stream but its great for multilingual where the model can switch between multiple languages. This is why I choose it even with a sacrifice on speed.
Other models are faster and cheaper and stream.
Model Providers:
OpenAI - STT & TTS ( I use, very good in many ways )
Deeepgram - STT & TTS ( I use, very fast, good pricing )
Cartesia - New interesting, emotional
Neets - Some super cheap ( low quality ) options and obscure languages
Azure - Supposedly some of the best Spanish TTS available I need to try
and many many more.
Developer Frameworks
Six months ago you essentially had to do this from scratch.
Now there is a growing ecosystem of frameworks that can get you going faster and give you lots of free best practices that are a little tricky to build from scratch like VAD and "interruptions" and fast integrations to iterate through models and providers.
My favorite:
If your familiar with Langchain for LLM work its kinda like that for voice.
It's loosely coupled with Daily.co and brings a great VAD ( Silero Vad ), interruption management, and many model providers in a python package.
Check out this demo using a Pipecat template.
Pay close attention to the function calls ( when you hear the noise ) and the "interruptions" handling.
I'm currently using this framework for building all new features for Nuance.
Other Notable:
LiveKit Agents - More tightly coupled to Livekit infra then I like. Not as ready as Pipecat.
Managed Services
Some of you might be scratching your head wondering why do this at all?
There must be something like a "Shopify for AI Voice".
Your not wrong.
However all options have tradeoffs and since I'm a developer I often opt for the code options because they are tools I am productive with.
That said.
If you want to go Zero to MVP to Paying Customers as fast as possible and your needs are pretty generic you should use these tools.
I use this. It is great. You get everything I talked about and more and you can be live in minutes.
For example I had an idea for a veterinarian voicemail service. Took no time to have a demo live on the site. Much faster path to talking to customers than building anything.
You can have a WebRTC based agent live that can be accessed in a website or via a real phone number in minutes.
Want to have it do function calls to build an appointment setting AI?
You can have the function calls hooked up to a simple rest server in a matter of hours.
Just go try the demo on their home page.
Good prices too.
Expect something like $6 - $10 per hour for phone calls with AI.
Other Notable:
Wrapping Up
Now that I have saved you a few hundred hours of mistakes you should be able to build something interesting much faster.
We have just started a golden age of Voice Interfaces.
The iPhone will have native voice interaction that doesn't suck by 2025.
Your land lines and cell phones are no longer safe from developers. 😆
You might adopt voice in your business or build a business around Voice sooner than you expected.
I hope this guide was helpful.